
Alright, this is a continuation of System Architecture, a super broad subject I’ve been recently immersing myself in. I must admit, my last post was a bit poor in quality – I even left things hanging in the end. So I felt compelled to dive in deeper into an architecture known as “Distributed Systems”, yes in one lesson by Tim Berglund.. As the name of this blog post suggests, this is based off a youtube video I found – Distributed Systems in One Lesson.
So I was a bit hesitant on investing roughly 45 min of my time on a video that claims to cover a vast topic in that short a time. But hey, what’s 45 minutes? So I decided to proceed and outline a few important key points when it comes to Distributed Systems. Quick background on Tim – Tim is Director of Developer Experience at Confluence
What is a Distributed System and why they are terrible?
In a simple system, the below actions aren’t too complicated, however as Tim explains in his experience – complications arise when the system scales and gets larger.
– Store Data
– Computate Data
– Move Data
A formal definition of a Distributed System by Andrew Tannenbaum –
“A collection of independent computers that appear to its users as one computer.”
Examples of these include Amazon.com (AWS), Cassandra Cluster and Kafka.
Distributed Systems have 3 Characteristics
1. The computers operate concurrently
2. The computers fail independently
3. The computers do not share a global clock
Tim says… my goal here…
“Don’t do this. Get an easier job. Build a smaller system. Live in the country.”
I couldn’t help myself here but quote those exact words from the video. I’m excited to see what Tim has to say and his reasons why.
Single-Master Storage
Yes the simple days. You have a database that exists on one server. But as the scale slider gets larger, things get busier and busier. Typically in a web system there is more read traffic than there is write traffic. In a relational database, reads are usually cheaper than writes.
How do we scale reads?
Answer. Read Replication. However as Tim describes, we’ve already broken something with this system, we’ve created a distributed system it’s just not intentional (yet).
Well, what did we break?
We broke consistency due to propagation involved in Read Replication. Also as we continue to scale up and add more follower servers, the master server will eventually max out. So what do we do?
Sharding – splitting up the database
Not a new technique. But with this system, we’ve again broken consistency and the data model. Now we can join across shards, we have completely different database from shard to shard. This works “sometimes”.
Alright, what are some viable solutions?
When indexing, removing table joins no longer become a stable solution in scaling a database we en up denormalizing, quite the opposite of what a relational database is supposed to be.
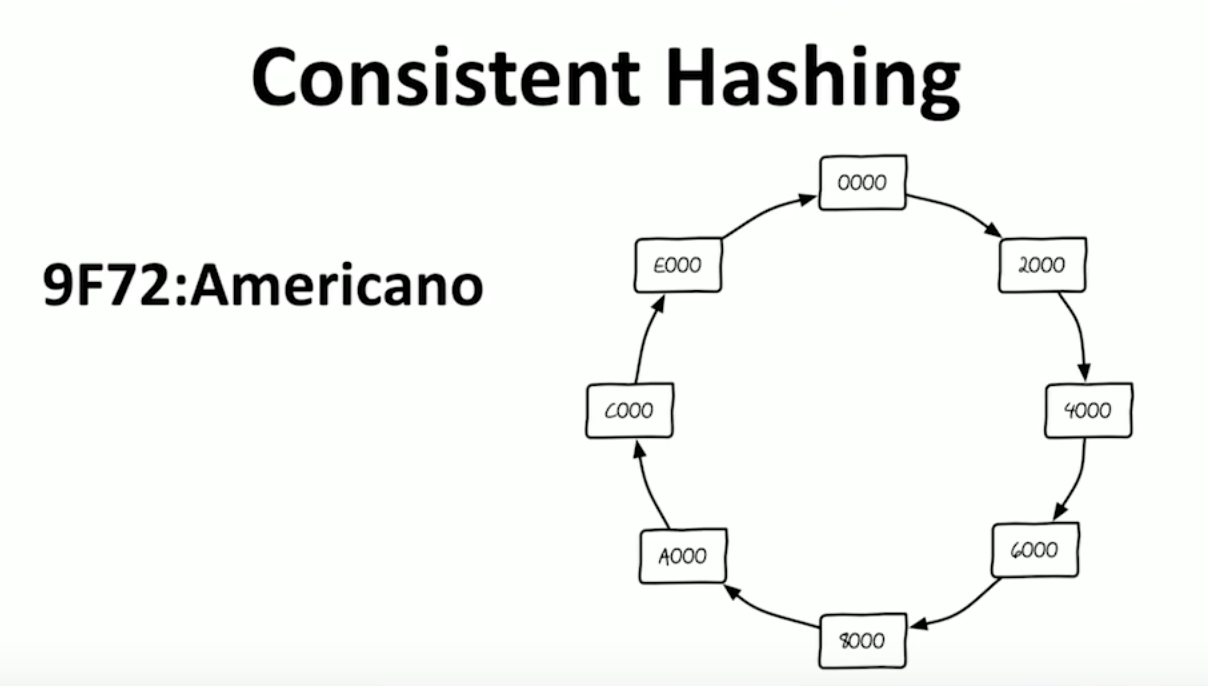
Consistent Hashing
Consistent hashing requires that the hashing algorithm stays constant and each node is assigned a hash as seen below. Then some data, key value pair is is stored on each node.
Replication
With replication, we can replicate each key value pair on other nodes. As mentioned earlier, since each system stands independently from each other should one fail (hardware failure or some anomaly), a distributed system allows for fail proof delivery.
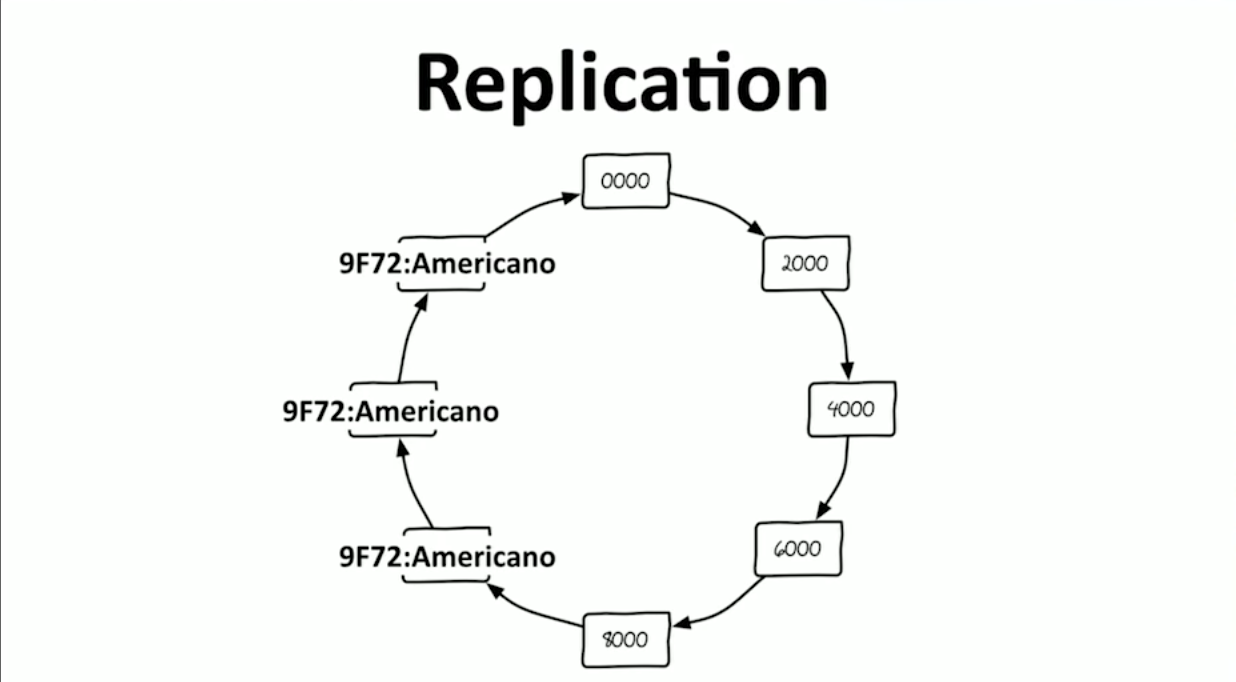
But there is an issue here as we are in the same attempt to solve the issue. Yes. Consistency. Now that we have several copies of data, this causes a consistency issue. When we expect a successful read or write from a database, we expect all copies of data to be consistent across the board. Well what if one or two nodes fail in a read? Or let’s say one or two nodes fail in a write? Whoa, these are some major issues.
C.A.P. Theorem
1. Consistency
2. Availability
3. Partition Tolerance
The short version of the underlying issue using the C.A.P. method – you can’t have all three. Put simply, we can only achieve 2 of the 3 things, not all three. This presents the same issue.
Alright enough with Storage. Let’s move on to the next topic – Distributed Computation.
Distributed Computation
Again, really easy if you only have a single processor. But… you have multiple computers and you’re trying to distribute computational tasks across multiple computers – this makes things harder.
Hadoop and MapReduce
– MapReduce API
– MapReduce job management
– Distributed Filesystem
– Enormous ecosystem
… but this a legacy system.
Spark API, similar to Hadoop
Instead of Map, we have Transform. Instead of Reduce we have Action.
– Scatter/gather paradigm (similar to MapReduce)
– More general data model(RDDs, DataSets)
– Provides objects. More general programming model (transform/action)
– Storage agnostic
Kafka – distributed streaming platform
Enter Kafka
– Focuses on real-time analysis, not batch jobs
– Streams and streams only
– Except streams are also tables (sometimes)
– No cluster required!
– Streams are first class citizens
– Not just a messaging framework, but also a computational framework for distributed systems
Alright on to your last topic – Messaging
Messaging in Distributed Systems
– Means of loosely coupling subsystems.
– Build little chunks of functionality
– Version and release messaging functionality
– Messages consumed by subscribers
– Created by one or more producers
– Organized into topics
– Processed by brokers
– Usually persistent over the short term
Messaging Problems
Producer -> Topic -> Consumer– What if producer gets too big? – What if a topic gets too big – too much data retention – Or messages get too big – Transacting messages too fast (read/write) – What if one computer isn’t reliable enough?
Revisiting the Kafka Distributed Messaging System
Definitions

– Message: an immutable array of bytes
– Topic: a feed of messages
– Producer: a process that publishes messages to a topic.
– Consumer: a single-threaded process that subscribes to a topic
– Broker: one of the servers that comprises a cluster
So Kafka is a great messaging solution, but when we start getting into replication – this is where things start getting complicated.
Lambda Architecture
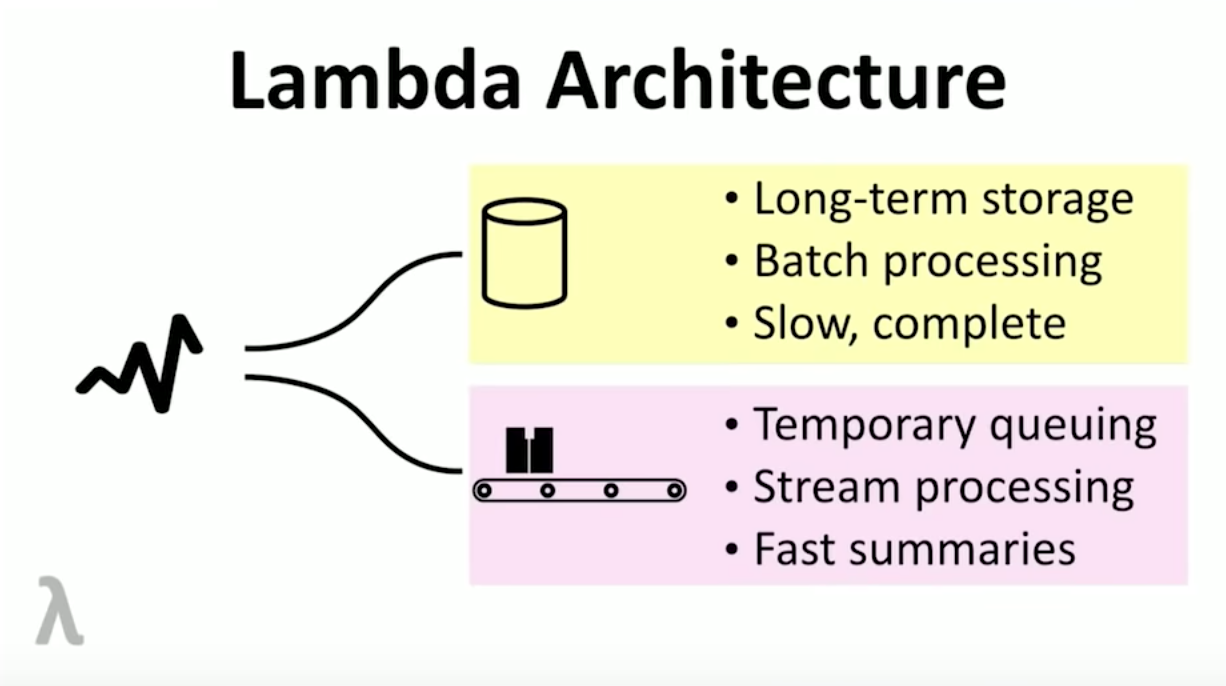
Why was this bad though? Well, as Tim explains – this forced people to write two versions of code, one for stream and one for batch.
With Streams
Now that we have a messaging bus. Stop taking events and writing them to some place in a database. Let them be events and process them in-place through a stream processing API. Events are consumed on a as-needed basis.
Conclusion:
This was a super interesting intro to distributed systems and its pitfalls. I myself have run into this while prematurely designing a database with scaling in mind. As I planned for the future, I ended up denormalizing the database and I was slowly spiraling down into a mess I could no longer translate to my colleagues.
Stay tuned for more blog topics covering System Architecture.


